MoCo:视觉对比表征学习
MoCo 是计算机视觉大牛何凯明组的工作,从 2019 年发表的 MoCo V1 到 2021 年的 MoCo V3 研究重心一直是基于对比学习的视觉表征模型学习,随着近几年视觉领域训练方法从有监督到无监督、模型骨架从 CNN 到 Transformer 的变化,MoCo 也不断地对方法进行了升级改造,持续推动自监督对比学习取得进展。本文将详解介绍 MoCo V1/V2/V3 方法,看作者是如何围绕一个问题不断给出优化解决方案的。
1. MoCo V1
1.1 概述
基于对比学习的无监督视觉表征学习方法取得了较大的进展,这类方法有望使得视觉表征学习摆脱对监督数据集(如 ImageNet)的依赖。MoCo V11从统一视角将对比无监督表征学习进行了概述:
简而言之,对比学习就是在查字典。字典中的
key来自对数据集的动态采样,并通过表征模型(key encoder)对其向量化,而对比无监督学习就是训练表征模型,使得query样本被向量化后(query encoder)能够接近跟其匹配的key,并同时远离字典中的其它key。这里 key encoder 和 query encoder 就是要进行学习的表征模型,下文会介绍二者之间的关系 👇。
既然是在查字典,论文指出该字典应满足以下两个要素
- 字典要足够大:由于字典内容是对数据集的采样表示,越大的字典越能够接近真实的全量数据分布。
- 字典在训练时要保持一致性:字典在训练过程中动态构建,因此需要字典中的所有 key 样本以及训练时的 query 样本是由相同/相似的表征模型计算出来的,这样才能保证查字典是有意义的。
论文通过队列数据结构来实现这个字典,当前 mini-batch 数据进入队列,同时最老的数据会弹出队列,这样既保证了字典内容是动态采样的数据,又使得字典大小跟 mini-batch 大小无关,从而可以支持足够大的字典。
同时为了保持字典内容的一致性,论文中 key encoder 是基于 query encoder 进行动量移动平均得到的(momentum-based moving average),也即 key encoder 并非完全基于每个 mini-batch 进行更新,而是会保留模型的历史状态,进行逐步缓慢的更新。
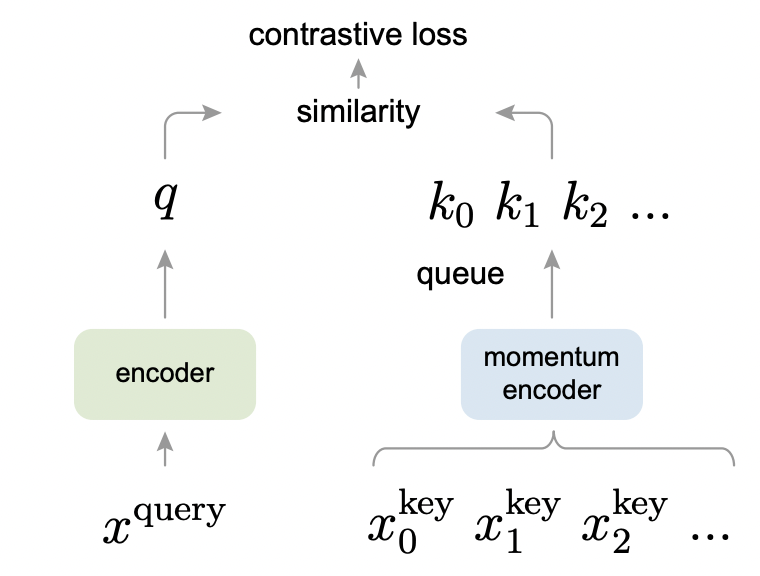
1.2 方法
1.2.1 学习目标
MoCo 认为对比学习就是在以查字典的方式来训练表征模型。假定经过 query encoder 编码后 query 计作 $q$,此时字典中被 key encoder 编码向量有 ${k_0, k_1, k_2, \dots}$,其中的某个 $k_+$ 同 $q$ 构成正样本对,对比学习损失函数希望正样本对彼此之间靠近且负样本对彼此之间远离,也即优化如下损失函数:
$$ L_q = \frac {\exp(q \cdot k_+ / \tau)} {\sum_{i=0}^{K} \exp(q \cdot k_i \tau)} $$
其中 $q=f_q(x^q)$ 和 $k=f_k(x^k)$ 分别表示 query encoder 和 key encoder 的编码结果,$q$ 和 $k$ 之间相似性度量采用了点积方式;$\tau$ 温度系数用来控制预测分布的平滑程度。论文中 query encoder 和 key encoder 都采用了 ResNet 骨架,当然理论上讲 MoCo 方法也可以用于其它模型骨架。
一般来说,无监督/自监督学习会涉及代理任务(pretext task)和损失函数的设计。MoCo 重点关注上述损失函数的设计,至于代理任务则采用了较为常规的判别任务:一张图片经过随机的两次数据增强处理后得到两个副本,它们分别被 $f_q$ 和 $f_k$ 编码得到 $q$ 和 $k_+$ 构成的正样本对,同时 $q$ 跟来自队列中的其它数据构成负样本对,任务就是要区分这些正负样本对。
1.2.2 动量对比
论文先将对比学习视为查字典,并指出该字典应该够足大且前后尽量保持一致,然后就是设计如何维护这个字典,这部分内容是论文的核心思想。
对比学习过程中字典是动态变化的,一方面会随着训练不断采样新数据加入字典中,另一方面用于字典编码的 key encoder 是随着训练不断变化的。前面提到为了利于表征模型训练,我们希望字典尽可能大,同时也希望编码字典内容的 key encoder 尽量前后一致。论文中通过队列来实现字典,动态采样数据进入队列可以保证字典足够大。此外通过引入动量更新(momentum update)机制使得 key encoder 能够保持一致性。
字典通过队列实现。在训练时,字典中的内容就可以充当负样本,并且由于该字典单独维护跟 mini-batch 大小无关,因此极大降低显存使用量,使得字典可以非常大,同时字典大小可作为超参数独立调优。随着训练进行,当前 mini-batch 会加入队列,同时最老的数据会从队列退出,队列的好处在于提供了数据动态采样的能力,同时将老数据丢弃,防止编码数据的前后不一致问题。
模型进行动量更新。字典内容的表征模型 $f_k$ 由于要构造训练输入数据,因此无法随着后向传播一起更新。如果在每次训练更新完 $f_q$ 后将参数拷贝到 $f_k$ 呢?对于该方案,论文经过实现指出,由于 $f_k$ 变化太频繁,致使字典中内容前后不一致,学习效果不理想。为此论文提出动量更新机制:
$$ \theta_k \leftarrow m * \theta_k + (1-m)*\theta_q $$
其中 $\theta_k$ 和 $\theta_k$ 分别是 $f_k$ 和 $f_q$ 表征模型的参数;$m$ 是动量更新系数,介于 0 到 1 之间,论文指出该系数取值应该较大(如 0.999),以保证 $f_k$ 变化较为缓慢。
论文基于线性分类评估方法(下文会介绍)对比了不同动量更新系数下的效果:

从实验的几组参数看,动量更新系数越大则效果越好,并且对系数十分敏感。极端的情况是系数等于 0,也即直接将 $f_q$ 的参数拷贝到 $f_k$,此时训练失败无法收敛。
同其它对比学习机制之间的比较。
目前有几种经典的对比学习优化范式/机制,除了本文的 MoCo 外,还有端到端机制(end-to-end)和记忆库(memory-bank)机制,它们之间的不同主要在于如何维护字典以及 key encoder 是如何更新的。
端到端机制(见下图(a)),也即使用当前 mini-batch 作为字典,query encoder 和 key encoder 可能共享或不共享,key encoder 随着后向传播一起更新。其优点在于实现简单,并且字典内容由同一个 key encoder 编码,必然满足一致性。缺点在于字典大小同 mini-batch 相同,需要较大 batch size 来提升收敛速度和效果,因而对显存使用有较高要求。更多关于端到端机制的细节,可以参考代表工作 SimCLR2。
记忆库机制(见下图(b)),memory bank 中存放了数据集中全部样本,在训练时从中随机采样一部分作为当前 mini-batch 的负样本,因此可以支持非常大的字典。同时当 memory bank 中的样本被采样到后会进行动量更新,注意这里更新的是样本而不是 key encoder,因此也意味着某次采样的负样本字典其实是来自历史上多次更新的样本,所以一致性就差一些。
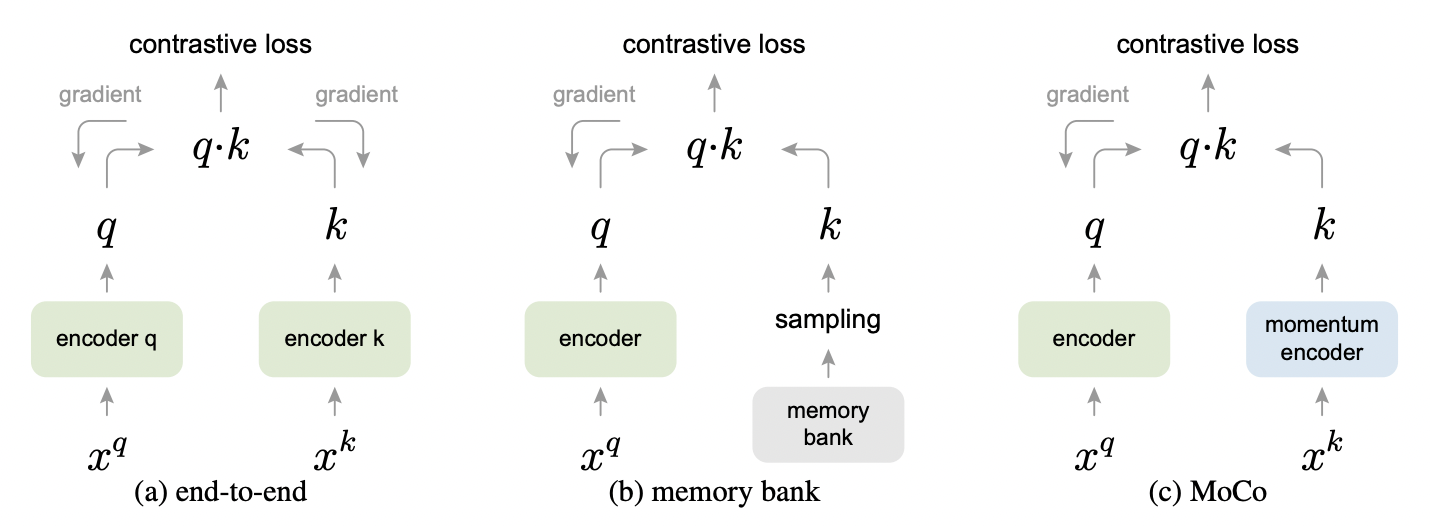
通过比较可以发现,MoCo 方法兼具了端到端和记忆库机制的优点,既可以通过队列采样来高效利用显存,提供足够大的字典,又可以通过对表征模型动量更新来保证前后编码内容的一致性(可以认为 MoCo 是一种基于 memory queue 的对比学习机制)。
论文基于线性分类评估方法(下文会介绍)对比了各种对比学习机制之间的效果差异:
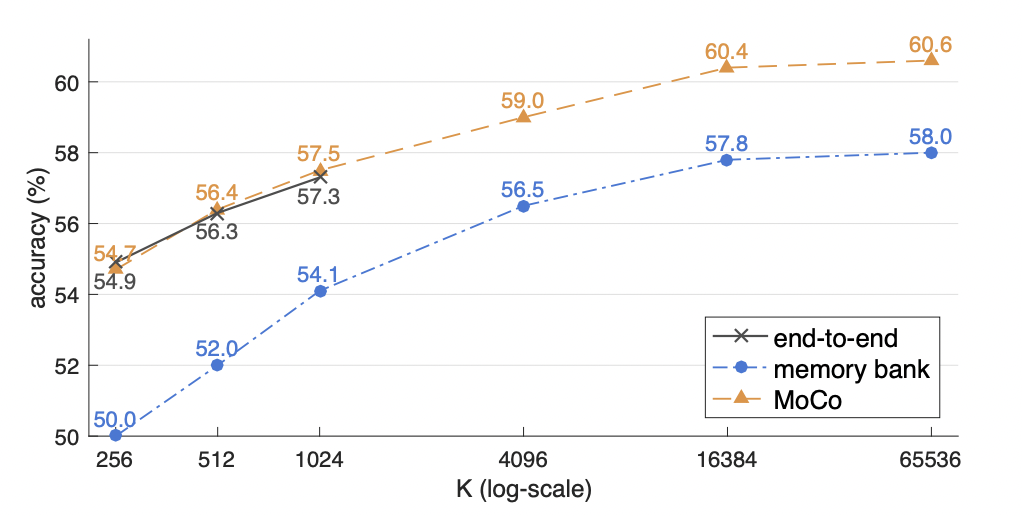
首先三种机制都可以随着 batch size 变大而效果变好,这个说明字典足够大是有意义的;end-to-end 机制能够支持的 batch 大小有限,对于 32GB 显存机器来说最大可支持 1024 大小,并且当 batch 变大以后模型训练优化会不稳定;memory bank 机制和 MoCo 机制都可以支持非常大的 batch size,不过 memory bank 在不同 batch 大小情况下均落后于 MoCo 两到三个点。
1.2.3 随机打乱 BN
论文采用的表征模型是 ResNet3,里面含有标准 Batch Normalization (BN) 计算结构。论文通过实验指出,这个标准 BN 结构不利于表征模型学习,猜测可能由于 BN 结构存在 batch 内部通信,造成信息泄漏 ,使得模型很容易就欺骗了训练任务。论文采用了随机打乱 mini-batch 中样本顺序的方法来解决了该问题,具体做法:
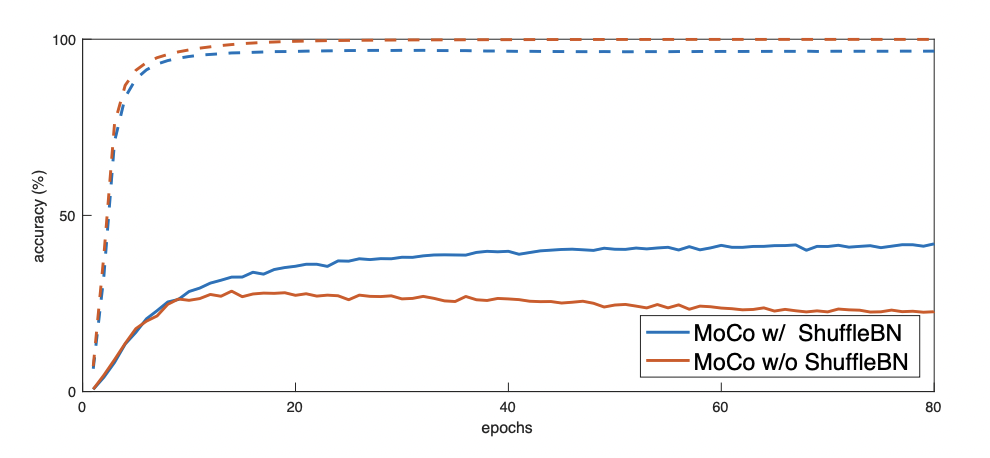
上图虚线是训练时代理任务上的 accuracy,实线是验证集 accuracy。可以看到没有使用 shuffle BN 时,训练集上效果很快达到 99.9% 以上,但随着训练进行验证集效果反而在下降,显然由于 BN 信息泄漏出现了过拟合现象。当使用了 shuffle BN 时,随着训练进行验证集效果就在提升了,可见 shuffle BN 克服了标准 BN 带来的信息泄漏问题。
1.3 效果
1.3.1 线性分类评估
线性分类评估方法是无监督/自监督表征学习的常规评估手段之一,也即用表征模型抽取图片特征,送入线性分类器进行有监督的分类任务学习,其中表征模型被固定住了,并不参与分类任务训练的反向传播过程。
论文对比了同样基于无监督/自监督学习的表征模型,因为不同表征模型使用的模型骨架和参数量不同,公平起见不同模型之间的对比,应该在参数量相当条件下进行:
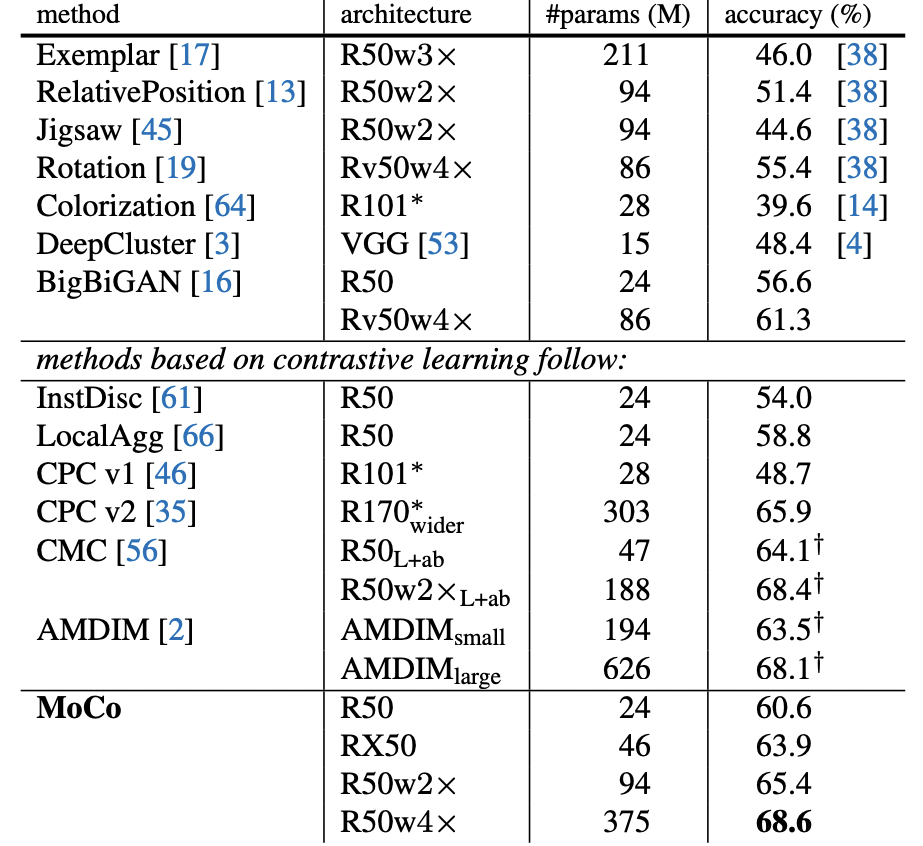
以 R50 24M 参数量为基准来看,MoCo Top-1 Acc 为 60.6%,超过同类方法;如果参数规模进一步放大为 R50w4x 则 Acc 可达到 68.6%。
1.3.2 迁移学习效果评估
不论是基于监督学习还是无监督学习的预训练,其目的都是为了能够将训练好的表征模型迁移到下游任务中。那从直观上来看,怎么才能说表征模型训练效果好呢?理想情况下,如果表征模型能够在众多广泛的下游任务上 finetune 效果好(迁移学习),并且对下游任务训练数据需求较少,那就是很好的模型了。
论文对比了 MoCo 无监督训练的表征模型和 ImageNet 上基于图片分类任务训练的有监督表征模型,二者在众多视觉任务上的表现(含目标检测、语义分割、姿态估计、关键点检测等任务)。由于实验结论较多,这里就不贴了,感兴趣的小伙伴可以去论文看下哈 🍼。
1.4 小结
MoCo 以查字典的视角统一了当前几种对比学习的经典范式,指出表征模型训练效果会受到字典大小以及内容前后一致性的影响,创造性的提出用队列来维护一个动态字典,同时基于动量方式来更新表征模型。通过这样的设计,使得对比学习负样本的数量不再受制于 batch 大小,而是可以直接从队列中获取,并且动量更新保证了队列内容的前后一致性。
2. MoCo V2
2.1 概述
MoCo V1 发布不久后,SimCLR2 论文出现了(基于 end-to-end 机制),该论文指出他们提出的对比学习框架使得自监督预训练方法几乎可以跟有监督方法打成平手。而 MoCo V1 虽然给出了一套通用对比学习机制(基于 memory queue 机制),但效果上跟 SimCLR 差距还是很大的。MoCo 研究者指出并非论文给出的对比学习机制落后,而是 SimCLR 使用了更多技巧和精细化的设计,只要把 SimCLR 这些思路借鉴过来,MoCo 照样很能打,这就是 MoCo V24 文章的由来。
MoCo V1 提到对比学习就是在查字典,不同对比学习机制之间的差异在于,负样本是如何维护和更新的。下面从 batch 数据处理的角度来比较下 SimCLR 和 MoCo 这两种范式的异同:
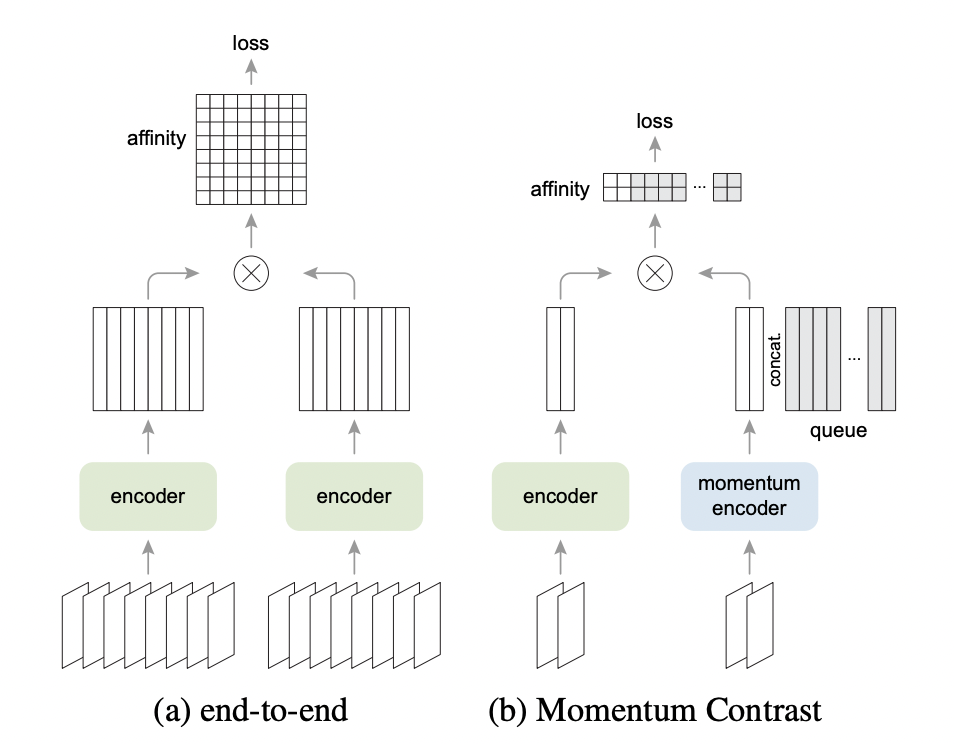
SimCLR (end-to-end) 方法用同一个 encoder 编码当前 batch 中的 query 和 key,对比学习损失计算时负样本就来自于同一个 batch 中;MoCo (momentum contrast) 方法分别用 encoder 和 momentum encoder 来编码当前 batch 中的 query 和 key,对比学习损失计算时负样本来自当前 batch 再加上 memory queue 中维护的样本。
既然 MoCo V2 主要改进是将 SimCLR 借鉴过来,那先来看看 SimCLR 有哪些精细化设计是 MoCo V1 所不具备的:
- SimCLR 在预训练阶段为 encoder 添加了一个 MLP 头结构,但下游任务迁移时并不使用这个 MLP 头。这样做的动机在于,预训练的代理任务本身,其实是需要一个额外参数层来学习的,否则所有信息都会被学习到 encoder 中。
- SimCLR 尝试了裁剪、缩放、颜色变换等较为复杂的数据增强手段,而 MoCo V1 的数据增强手段相对要简单一些
MoCo V2 指出只要把 SimCLR 这些设计照搬过来,同时再配合 MoCo V1 提出的查字典对比学习机制(memory queue),MoCo 方法的效果可以超越 SimCLR,并且具备一些独特的优势,比如 SimCLR 这种端到端的方法依赖非常大的 batch size,甚至需要借助 Google TPU 来训练,但 MoCo 机制只需要普通的 GPU 机器即可。
2.2 效果
由于只是借鉴了 SimCLR 的思路,具体方法细节感兴趣可以参考 👉 SimCLR 论文2。
论文分别进行了线性分类评估(ImageNet 数据集)和目标检测任务微调评估(VOC 数据集),首先验证了 SimCLR 各种技巧叠加对 MoCO 的影响:
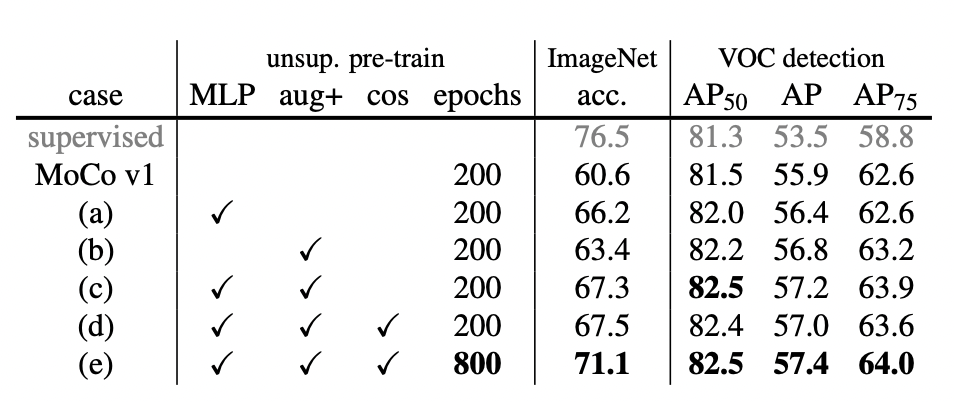
进一步对比 MoCo 和 SimCLR 在相当训练步数前提下,二者在线性分类任务上的效果差异:
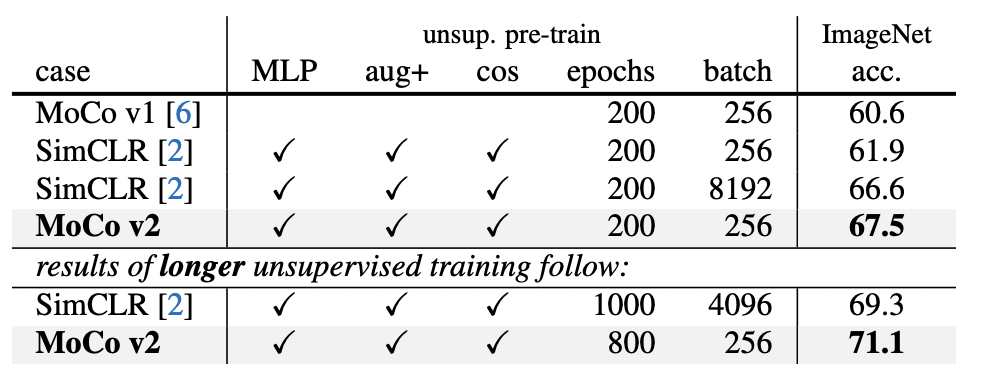
当训练 200 轮时,SimCLR 将 batch size 从 256 提升到 8192,accuracy 才能达到 66.6%,而 MoCo V2 仅需要 256 大小 batch 就可以达到 67.5%;并且随着轮数增加后,MoCo V2 可进一步将 accuracy 提升至 71.1%。
2.3 小结
MoCo V2 在下游任务上的迁移效果以及对训练资源的要求上都要比 SimCLR 更具优势。MoCo V2 继承了 MoCo V1 对比学习机制,同时又引入了 SimCLR 中的 MLP 和数据增强等技巧,最终在下游线性分类和目标检测任务上的效果超越 SimCLR。同时 MoCo 使用的对比学习机制相比 SimCLR 这种端到端机制需要更少的显存资源,只需要在传统 GPU 上即可训练,而 SimCLR 由于对超大 batch size 的依赖,需要借助 Google TPU 这种特殊资源才能训练。
3. MoCo V3
3.1 概述
这篇论文重点在于研究以 Vision Transformer (ViT)5 为模型骨架的 CV 自监督对比学习方法。文中指出以 CNN 为骨架的表征学习方法得到了广泛研究应用,相关训练优化技巧都为大家熟知,但基于 ViT 的自监督表征学习方法由于最近才兴起,训练优化技巧并没有被深入研究。虽然已经有关于 ViT 自监督学习的不少研究结果,并且取得了不错的效果,但论文经过验证发现 ViT 训练过程往往伴随着不稳定现象,这种不稳定虽不至于使得训练无法收敛,却意味着训练过程其实是存在部分失败的情况。
MoCo V36 论文对 ViT 自监督对比学习时的 batch 大小、learning rate 大小以及优化器等关键要素进行了大量实验,验证了不稳定现象的存在,基于对训练梯度的归因分析,给出一个缓解不稳定现象的简单技巧。
3.2 方法
3.2.1 MoCo V3
为什么要采用 ViT 骨架来研究 CV 自监督学习?
Transformer 模型结构天然适合表示数据的长距离依赖关系,并且运行效率较高,具有诸多优势,已经在 NLP 领域得到非常成功的应用。随着 Vision Transformer (ViT) 的问世,Transformer 模型在 CV 领域也逐渐受到研究者的重视,正在逐渐成为跟 CNN 模型并驾齐驱的 CV 模型骨架,有大一统 NLP 和 CV 模型结构的趋势。正是基于这样的考虑,论文决定采用 ViT 作为自监督学习的骨架。
为什么要采用对比学习这种自监督的范式?
自监督学习本质上是在无监督数据上设计一个代理任务(pretext task),通过对代理任务的学习来得到一个对下游任务有用的表征模型。可见代理任务不同则自监督方法也不同,CV 领域目前被广泛研究的两种自监督学习范式:masked auto-encoding 和 contrastive learning。masked auto-encoding 范式借鉴 NLP 领域的思路,通过对遮掩的像素或图像块进行复原来学习表征模型。对比学习(contrastive learning)范式则以 MoCo/SimCLR 等工作为代表,通过识别数据增强的正样本来学习表征模型。目前来看对比学习范式取得了不错的效果,甚至在某些下游任务上可以跟有监督学习方法打成平手。
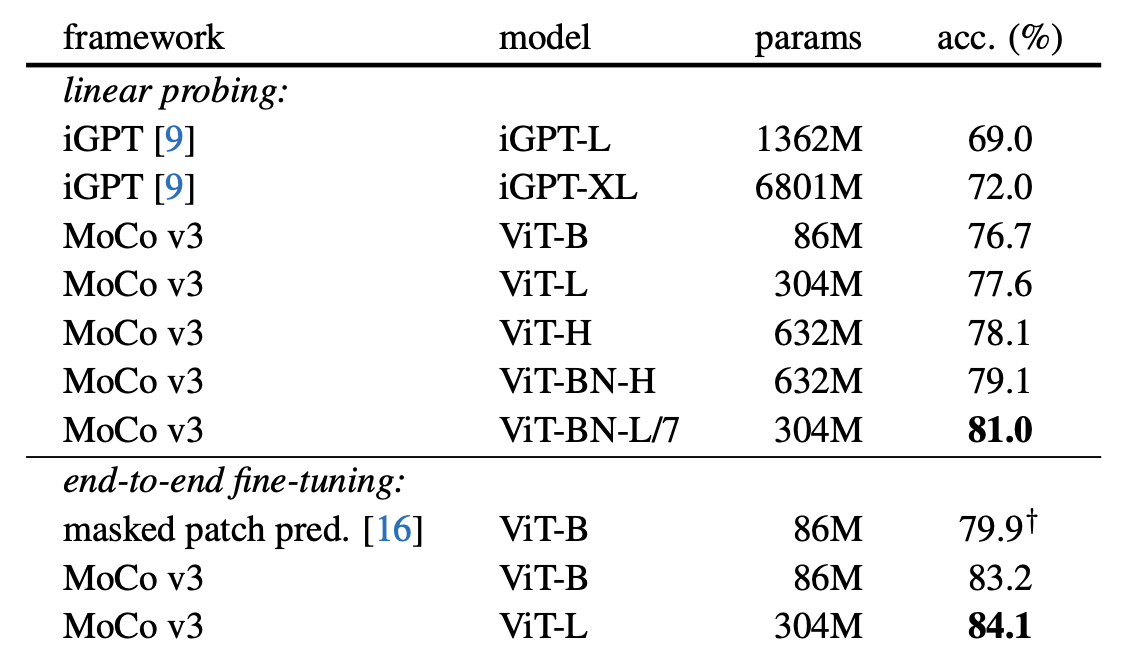
比较了 masked auto-encoding 和 contrastive learning 两种自监督学习范式,其中 iGPT 和 masked path pred 都属于 masked auto-encoding 范式。可以看到在 ImageNet 分类数据集上 linear probing 和 fine-tuning 两种下游评测方式,contrastive learning 自监督学习都具有极大优势。
MoCo V3 依然延续了 MoCo V1/V2 对比学习+动量更新的方法,主要差异有以下几点:
- 论文研究的表征模型骨架从 CNN 变为 ViT
- 虽然沿用了对比学习范式,但取消了动态采样负样本的 memory queue 机制,V3 中负样本都来自同一个 batch
- 对比学习损失函数采用对称形式,也即 x 数据增强得到的 x1 和 x2 两个副本都既可以当 query 又可以当 key

3.2.2 不稳定现象
MoCo 学习框架对表征模型是哪种骨架(CNN or ViT)没有任何假设,因此理论上来讲,把骨架从经典的 CNN 结构换成 ViT 应该十分简单。不过论文指出在训练 ViT 对比自监督学习时,会遇到不稳定现象,并且不稳定导致的问题会被看起来还不错的训练结果给隐藏起来。论文对训练过程中的 batch 大小、learning rate 大小等关键因素进行了实验分析,追查这种不稳定现象的根源(🗣 大佬这种思考问题、定位问题的能力是真强啊)。
【实验】不同 batch 大小,训练时 kNN 监控以及训练完成后的线性分类评测效果如下:

batch 从 1k 到 2k 时,符合 batch 越大训练效果越好的预期;当 batch 到 4k 时,可以看到训练时监控曲线会偶尔跳水式下降又上升,论文推测应该是训练时陷入局部最优又跳出来重新开始学习导致的,最终在线性评测上 4k 跟 2k 相比 acc 仅降低了 0.4% (72.6%->72.2%),显然这么微小的效果降级是很难被发现的;当 batch 到 6k 时,可以看到不稳定现象越发严重,并且整体上看训练效果比之前下降了大约 3%,最终线性评测 acc=69.7%;综上可见,这种不稳定性会随着 batch 增大到一定程度后越发严重,导致的后果并非训练无法收敛,而是存在一定程度的效果降低,因此这个问题往往会被大家所忽视。
【实验】不同 learning rate 大小,训练时 kNN 监控以及训练完成后的线性分类评测效果如下:

几组实验中当 lr=1.0e-4 时,最优效果,太小或太大 lr 都会降低 acc;当 lr=0.5e-4 时,训练较为稳定,但存在一定程度欠拟合,此时 acc=70.4% 是由欠拟合导致的;lr=1.5e-4 时,训练不稳定现象严重,此时 acc=71.7% 是由训练稳定性导致的;注:这里的 lr 是一个基准值,实际用于训练时的 learning rate 是跟 batch 大小有关的,具体换算关系为 learning rate=lr×BatchSize/256,上图实验中 BatchSize=4096。
【验证】梯度突变导致不稳定发生,监控训练时模型的第一层(即 patch projection 层)和最后一层参数的梯度变化:

从上图可观察到第一层先于最后一层发生梯度的突变,因此论文推测不稳定现象先在浅层网络结构发生,然后再波及到整个网络结构。
【解决】采用了将模型第一层结构固定住的小技巧,缓解了训练不稳定:
论文提出一种简单的技巧,通过把第一层固定住(也即使用随机初始化的 patch projection 层,图片到 embedding 这个过程是不可学习的)来缓解不稳定现象的发生。

模型第一层固定住时,在不同学习率下,训练曲线都更平滑了,并且评测效果均有提升,对于 lr=1.5e-4 帮助更大。可见这个小技巧对缓解不稳定现象有较大作用。
除了 MoCo 范式外,论文还对 SimCLR/BYOL/SwAV 等自监督学习方法进行了实验,结果表明固定第一层这个技巧不仅仅对 MoCo 有效,对其它自监督方法也有效。不过论文也指出,固定第一层仅仅是把解空间变小,使得模型训练更容易些,并没有从本质上解决该问题,当采用较大学习率时依然训练会不稳定,不稳定现象必然跟模型所有层均有关联。
3.3 效果
跟其它 ViT 自监督学习方法进行对比:

对 Resnet-50, Vit-Small, Vit-Base 三种模型骨架进行了实验,所有自监督方法都使用了固定第一层的技巧,并且使用的 lr 和 wd 都一样,可见对于不同模型骨架来说 MoCo 都要比其它方法要好。
接下来通过消融实验来进一步探究 MoCo V3 自监督学习中哪些因素起到了关键作用,ViT 模型又具有哪些优缺点。
不同位置编码方式对表征学习效果的影响:

采用 sin-cos 位置编码方式效果最好,不过即便没有任何位置编码 none 效果也仅降低 1.6%,可见 ViT 模型能够从一堆没有位置关系的 patch 中学习到有用表征。同时也说明添加 sin-cos 位置信息后,模型也并没有充分的利用起来。
特征池化方式对下游分类效果的影响:

CLS 池化和均值池化都能有不错的效果,但如果保留 ViT 最后一层的 LN 规范化则效果就会差很多。
BatchNorm 作为 ResNet 模型的标配,但在 ViT 模型中并非必须,仅是锦上添花的事情(可提升 2.1%):

为了验证 MoCo V3 表征学习模型的泛化性能,在不同下游任务中进行迁移学习,效果如下:

在 ImageNet-1K 数据集上,MoCo V3 模型的迁移学习能力比有监督预训练模型 ImNet supervised 要强,并且模型规模达到 Huge 仍并非过拟合。另外 random init 指的是,直接用随机初始化 ViT 在下游数据集上学习,由于欠拟合,模型规模越大效果反而会越差,可见不论是自监督还是有监督的预训练对于下游任务都是很有必要的。
3.4 小结
MoCo V3 同样继续研究自监督视觉表征学习,不过模型骨架从之前 V1/V2 中采用的 ResNet 转投到了 ViT,同时抛弃了之前的 memory queue 转投到了 end-to-end 的对比学习机制。作者指出基于 ViT 的自监督学习还没有被社区充分探索,因此存在不少坑。为此作者进行了大量的实验,提出了缓解 ViT 训练不稳定的一个简单技巧,对比了不同 ViT 和 Resnet 之间的差异,对比了有监督和自监督之间的差异,对比了不同自监督方法之间的差异。整篇文章对问题的思考、假设、验证都十分翔实,向大佬致敬 👍。
参考资料
-
MoCo V1: https://arxiv.org/pdf/1911.05722.pdf ↩︎
-
SimCLR: https://arxiv.org/pdf/2002.05709.pdf ↩︎ ↩︎ ↩︎
-
MoCo V2: https://arxiv.org/pdf/2003.04297.pdf ↩︎
-
MoCo V3: https://arxiv.org/pdf/2104.02057.pdf ↩︎